2025年12月12日、GPT-5.2がローリングアウトしたタイミングでXのOpenAIアカウントから発表された以下の図の簡単な解説です。
GPT-5.2は、事前知識によらず思考の枠組みをその場で組み立てられるかを問うARC-AGI-2において高スコアを示しており、AGIに必要とされる能力の一部で明確な前進を示しています。
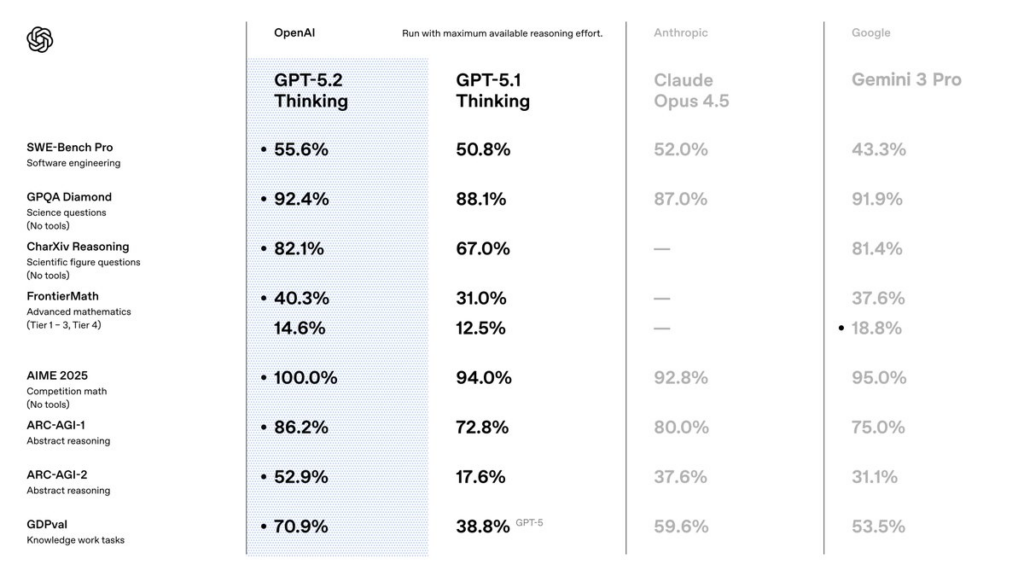
以下、日本語による簡単な解説です
| ベンチマーク | 何を評価するためのものか | GPT-5.2 Thinking | GPT-5.1 Thinking | Claude Opus 4.5 | Gemini 3 Pro |
|---|---|---|---|---|---|
| SWE-Bench Pro | 実在するソフトウェアのコードを読み、バグ修正や機能追加を行い、テストまで通せるか(実務ソフトウェア開発力) | 55.6% | 50.8% | 52.0% | 43.3% |
| GPQA Diamond | 検索や暗記では解けない、大学院レベルの科学問題を論理的に推論できるか(科学的理解力) | 92.4% | 88.1% | 87.0% | 91.9% |
| CharXiv Reasoning | 科学論文(図・数式・説明)を読み、その内容を踏まえて推論できるか(論文読解・科学推論力) | 82.1% | 67.0% | ― | 81.4% |
| FrontierMath (Tier 1–3) | 定型ではない高度な数学問題に対し、解法そのものを考え出せるか(先端数学的思考) | 40.3% | 31.0% | ― | 37.6% |
| FrontierMath (Tier 4) | 研究者レベルの極めて難しい数学問題を扱えるか(最難関数学推論) | 14.6% | 12.5% | ― | 18.8% |
| AIME 2025 | 数学オリンピック予選レベルの競技数学問題を正確に解けるか(競技数学能力) | 100.0% | 94.0% | 92.8% | 95.0% |
| ARC-AGI-1 | 図形や色の変換ルールを見抜く、基礎的な抽象パターン認識ができるか | 86.2% | 72.8% | 80.0% | 75.0% |
| ARC-AGI-2 | 事前知識に頼らず、初見の抽象ルールをその場で理解・一般化できるか(汎用知能に近い能力) | 52.9% | 17.6% | 37.6% | 31.1% |
| GDPval | 調査・要約・判断など、実務や経済活動として価値のある知識労働をどれだけこなせるか | 70.9% | 38.8% | 59.6% | 53.5% |
性能比較図の解説
左側に並ぶベンチマークの意味
図の左側に縦に並んでいるのが、評価に使われたベンチマーク(試験)です。それぞれ「測っている能力」がまったく異なります。
SWE-Bench Pro
評価対象:実務ソフトウェア開発能力
実在するソフトウェアのコードを読み、バグ修正や機能追加を行い、テストまで通す必要があります。
これは「コードを書けるか」ではなく「現場で役に立つか」を測る試験です。
GPQA Diamond
評価対象:科学的な概念理解と推論力
大学院レベルの物理・化学・生物の問題で、検索や暗記では対応できない設計になっています。
科学知識を
理解し、因果関係として説明できるかが問われます。
CharXiv Reasoning
評価対象:科学論文を読んで考える力
arXivに投稿されている研究論文(文章・図・数式)を読み、
その内容について推論する問題です。
論文を
「読める」ではなく
「理解して考えられる」かを測ります。
FrontierMath
評価対象:最先端レベルの数学的思考
定型問題ではなく、
解法そのものを考え出す必要がある非常に難しい数学問題です。
人間でも、
数学の専門家クラスでなければ歯が立ちません。
AIME 2025
評価対象:競技数学の処理能力
アメリカの数学オリンピック予選レベルの問題です。
計算力と論理力が中心で、答えは数値一つ。
高度ですが、
型が決まった数学という点が特徴です。
ARC-AGI-1
評価対象:抽象パターン認識(基礎)
色や図形の変換ルールを見抜くパズル形式。
言語や知識はほぼ使いません。
IQテストに近い能力を測ります。
ARC-AGI-2
評価対象:真の汎用知能に近い抽象思考
ARC-AGI-1の上位版で、難易度は大幅に上がります。
事前知識が使えず、
初めて見るルールをその場で理解できるかが問われます。
現在のAIが最も苦手とする領域のひとつです。
GDPval
評価対象:実務・経済的価値のある知識労働
調査、要約、判断、意思決定補助など、
いわゆる「ホワイトカラー的仕事」をどれだけこなせるかを測ります。
実用性に最も近いベンチマークです。
なぜ ARC-AGI-2 に大きく差が出ているのか
性能比較表を見ると、ARC-AGI-2だけが他のベンチマークと明らかに様相が異なっています。
特に GPT-5.2 Thinking と他モデルの間に、大きな開きがあります。
これは偶然でも誤差でもありません。
ARC-AGI-2が測っている能力そのものが、他と質的に違うからです。
ARC-AGI-2は「知識」も「経験」も使えない
ARC-AGI-2の最大の特徴は次の点です。
- 事前学習した知識がほぼ役に立たない
- 過去に似た問題を見た経験も使えない
- その場でルールを発見し、一般化する必要がある
つまり、
「考え方そのもの」を即席で組み立てられるか
を問われます。
これは
数学・科学・プログラミングのように
「知識を当てはめる問題」とは根本的に違います。
なぜ従来型のAIはARC-AGI-2が苦手なのか
多くのAIモデルは、
- 膨大なデータからパターンを学習する
- 「それっぽい解き方」を再現する
という設計思想で作られています。
しかしARC-AGI-2では、
- 学習データの量はほぼ意味を持たない
- 言語能力の高さも直接は効かない
- 「それっぽさ」は即破綻する
という環境が用意されています。
そのため、
- 高性能でも点が伸びない
- 他のベンチマークでは強いモデルが急に弱く見える
という現象が起きます。
GPT-5.2 Thinking がここで強い理由
GPT-5.2 Thinking が ARC-AGI-2 で高い数値を出している理由は、
(公開情報から判断すると)
- 推論を段階的に分解する能力が高い
- 仮説 → 検証 → 修正を内部で回せる
- 正解を「思い出す」のではなく「構築する」挙動が強い
という点にあります。
これは知識量ではなく、
思考の運転方式の差です。
ARC-AGI-2は「AGIに近い」と言われる理由
ARC-AGI-2がしばしば
「AGI(汎用人工知能)への距離を測る試験」
と呼ばれるのは、
- 言語
- 数学
- 科学
- 文化
といった人間の蓄積知識をほぼ剥ぎ取った状態で、
それでもなお、意味のある推論ができるか
を問うからです。
(了)

小学生のとき真冬の釣り堀に続けて2回落ちたことがあります。釣れた魚の数より落ちた回数の方が多いです。
テクノロジーの発展によってわたしたち個人の創作活動の幅と深さがどういった過程をたどって拡がり、それが世の中にどんな変化をもたらすのか、ということについて興味があって文章を書いています。その延長で個人創作者をサポートする活動をおこなっています。